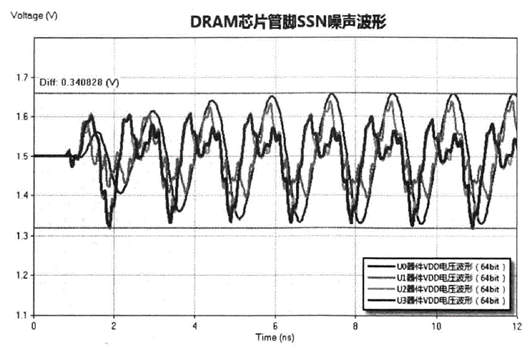
扫码关注
扫码关注
























简介
过去六十年里,摩尔定律面临过多次挑战,但半导体工程师总能找到突破,让芯片上的晶体管密度继续翻倍。然而,这背后的成本却在飙升。历来,缩小晶体管尺寸有助于提高芯片的运行速度。目前,制造商已能在硅芯片上形成仅有几个原子厚的微结构。但鉴于物理的极限,这些微结构无法无限缩小,虽然降温或降低电压等方法也能提速,但这些手段由于物理壁垒,限制了处理器速度的进一步提升。随着人工智能等技术的兴起,对提升计算能力的要求日益增长,同时,对于提升计算性能并降低能耗的需求也日益增强。
电子技术的发展面临着物理限制,而用户对计算能力的需求却在日渐增长。硅基光电子技术在这一矛盾中显现出其潜在的解决之道。我们已经见证了光纤取代铜线,为家庭互联网速度的飞跃提供了可能。光波频率远高于电子信号,意味着更高的数据传输速率。而且,光波能够叠加,即不同波长的信号能在同一光纤中同时传输,大大提升了传输效率。光电技术的发展已达到工业规模,以光学收发器为核心,这类设备能够同时发送和接收光信号。市面上现有的400G光学收发器能传输400 Gb/s的数据,800G型号也已面市。值得一提的是,400G设备的处理速度是普通办公电脑CPU的百倍。
在当下的数据中心,收发器是连接服务器或机架的关键,传输速度直接关系到整体性能。目前的限制在于,一旦数据信号进入服务器的电路板,就失去了光纤传输的优势,进而转向电子传输。如果能让光子信号更接近CPU和GPU,那么数据中心就能同时在速度和能效上取得突破。
然而,制造和管理光子数据链路要比传统电子数据链路复杂得多。光连接依赖于波导、镜子和耦合方案,这些都极易受到对准误差的影响。对准不当或耦合不良会导致信号损失,这是集成光子技术面临的一大挑战。
这些光子元件的集成通常采用半导体行业的CMOS制造工艺,但由于硅本身不发光,集成光子学解决方案需引入如铟磷、氮化硅等非传统材料来实现光学功能。目前也在探索使用玻璃等替代材料作为基板。英特尔针对玻璃作为芯片基板材料的研究,将Srinivas Pietambaram评为2023年度发明家,玻璃基板的使用预计将大幅提升互连密度和集成光互连的能力 [1]。
已经商业化的光 I/O 芯片
目前,将光信号高效地引入到板级和芯片级面临诸多挑战,这限制了此类架构的广泛应用。然而,随着技术进步,这一状况正在改变。硅谷初创公司Ayar Labs开发的TeraPHY芯片,是一款用于封装内光输入/输出的芯片,它在GlobalFoundries的45纳米工艺线上生产。该公司宣布,其芯片能以前所未有的低功耗(<<>5pJ/b)实现高达数十Tbps的带宽,覆盖距离可达2公里,展现了光电技术在提高传输效率和降低能耗方面的巨大潜力。
 图1展示了如何将光 I/O 芯片与电子芯片集成到同一封装中的一个实例,展示了光电技术在系统集成方面的进步 [1]。
图1展示了如何将光 I/O 芯片与电子芯片集成到同一封装中的一个实例,展示了光电技术在系统集成方面的进步 [1]。
Ayar Labs采取了将敏感的激光二极管(实际的光源)与I/O芯片及其产热的系统芯片(SoCs)分离的设计,以优化系统的热管理和性能(图2)。
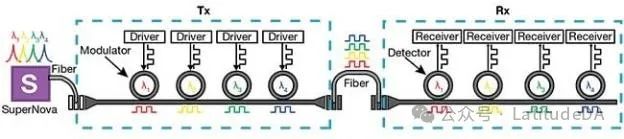 图2 Ayar Labs公司多波长SuperNova远程光源与其TeraPHY光输入/输出(I/O)芯片(发送端Tx)的示意图,通过光纤将信号发送至接收I/O芯片(接收端Rx)。图片来源:Ayar Labs
图2 Ayar Labs公司多波长SuperNova远程光源与其TeraPHY光输入/输出(I/O)芯片(发送端Tx)的示意图,通过光纤将信号发送至接收I/O芯片(接收端Rx)。图片来源:Ayar Labs
光源能够发射多达16种波长,支持256个通道的光输出,拥有4Tbps的双向带宽容量,而体积仅相当于智能手机SIM卡,展现了光源设计的高度集成和效率。
Ayar Labs最新展示的光场可编程门阵列(FPGA),将两个光 I/O 芯片与10纳米级FPGA织物芯片相结合,展现了光电技术在高性能计算领域的应用前景。该设备通过两个SuperNova光源提供动力,支持64个光通道,实现了在极低的功耗(<5pj>
光计算机:模拟的未来迄今为止的讨论展示了硅基光电子技术如何加速芯片间的数据传输。接下来的问题是,硅基光电子技术是否能够承担起核心处理任务。
一旦数据信号进入服务器的电路板,就会失去光纤的优势,转而采用电子传输方式。如果能将光子信号引入到CPU和GPU更近的位置,那么数据中心将在速度和能效上实现双重突破。
这一挑战涉及到光子与电子的根本物理特性的差异。电子带有电荷,因此可以存储在电容器中。当电子移动时,它们会产生电磁场,对周围的电子产生影响。电子流可以用来控制另一电子流,这正是晶体管的工作原理。关键是,电子在移动过程中会损失能量,以热的形式散发出去。
而光子不受电磁场影响——它们没有质量、没有电荷,且永远在运动中——因此没有光学电容器或晶体管。因此,构建基于光子的数字计算机不是一件简单的事。
因此,人们开始考虑使用光子构建模拟计算机。模拟计算机与我们熟悉的数字系统完全不同,它们专注于执行单一任务,并且是实时进行的。例如,一个棱镜就能实时完成对光束的傅里叶变换,将白光信号转换为空间分离的光谱,其精确度取决于探测器而非棱镜本身。
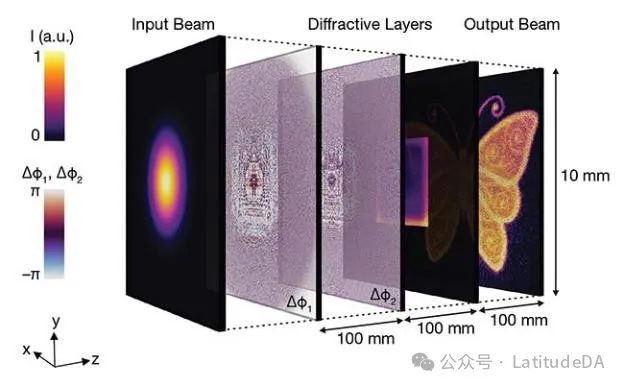 图3展示了一个更复杂的模拟计算机示例,其中一个圆形的相干激光束通过两个衍射光学元件(DOEs),经过不同相位延迟处理后形成全新的光束形状,如同蝴蝶般独特 [1]。
图3展示了一个更复杂的模拟计算机示例,其中一个圆形的相干激光束通过两个衍射光学元件(DOEs),经过不同相位延迟处理后形成全新的光束形状,如同蝴蝶般独特 [1]。
这种光束成型展示了通过光学配置来执行单一功能的模拟计算能力。在实际应用中,这一技术可用于激光制造过程的光束轮廓调整。从数学角度看,DOEs通过其相位延迟像素与相应光束的矩阵乘法操作,模拟了神经网络的工作原理,其中每个像素的相位变化相当于神经网络中每个节点的权重,而DOEs则相当于网络的各个层级。
这种操作方式类似于通过神经网络处理信号,本质上是对每层神经元进行一系列数学运算。机器学习算法帮助确定节点权重,以便神经网络的输出与预定目标最佳匹配。
这种光束成型的配置实际上是一种模拟计算机,专门执行单一任务。输入到输出的转换时间仅为光通过系统的时间。将静态DOEs替换为动态空间光调制器(SLMs)可以用于开发任务或优化过程。一旦通过机器学习确定了权重(即SLM上每点的相位延迟),模拟计算机便可投入运行。这种配置在神经网络应用中非常典型,比如工业图像识别和大型语言模型(如ChatGPT)等。尽管光束在相位掩模中的处理在视觉上引人注目,并且在激光材料加工中有应用,但要将其缩小到桌面计算机的规模仍面临挑战。要实现真正的光计算机,我们需要采取不同的方法。
真正的光计算机光电子技术在提高处理速度和传输速率方面的潜力如此明显,以至于科学家们在20世纪80年代就开始预言光计算机的到来。尽管贝尔实验室的尝试未能成功创造出光晶体管,但这并不意味着尽头。问题在于,光子之间不相互作用。
20世纪90年代,基于两个相干光波干涉的方法逐渐发展起来。这意味着,它们的场可以相加或相互抵消。这一效应取决于每个波相对于另一个波的相位,可以通过电光调制器来控制。Mach-Zehnder干涉仪(MZI)成为了大多数现代光计算系统中的基本单元或电路。在这些电路中,两个光波可以结合,并且可以通过相移器对每个波施加相位延迟(取决于可调节的电信号)。这种相位变化充当了光信号和电信号之间的乘法运算。
通过MZI阵列可以在光信号和施加到所有相移器的2D电信号之间进行矩阵乘法,这一点在21世纪初就已实现。这种设置几乎没有信号损失,因此提供了高能效,并且即使在一个芯片上集成了许多MZI的高度集成版本中也只产生了低废热。在2010年之后的十年里,MIT的量子光子学实验室不仅制造了这样的芯片,还开发了控制和读出硬件以及适当的校准技术。该实验室的几位合作者于2017年创立了Lightmatter公司。
Lightmatter解决了困扰光计算的多个挑战,包括在芯片上实现所有控制和读出电路,集成高密度存储,添加标准电子通信接口以支持像电子加速器一样的外部互动,并构建了使系统对最终用户即插即用的软件基础架构。
Lightmatter组装了一个概念验证系统,并构建了一个机架,其中两个传统的AMD EPYC 7002与16个Lightmatter的Envise光芯片一起工作,据报道,该系统的神经网络计算速度是NVIDIA的DGX-A100 GPU芯片的三倍。
Lightelligence,另一个MIT的衍生公司,也在2017年成立。该公司在2021年发布了其第一个光子计算处理器,并正在基于硅基光电子技术平台构建光子计算硬件。其最新的Hummingbird处理器包含一个电子处理器位于光子芯片之上的垂直堆栈,以及一个位于PCIe卡上的光网络芯片。
光子晶体管几家公司已经将光互连引入到晶圆级,并找到了一种将光和电信号相乘的方法。相移器的驱动器仍然是电的。能否将其转变为激光控制激光信号?“是的,这正是我们想要做的。”德国初创公司Akhetonics的创始人Michael Kissner表示。该公司致力于实现光子学的圣杯:一个光控制光的系统。
这在20世纪80年代几乎是天方夜谭,但随着封装和材料科学的进步,如今看来有很大的可能性成为现实。Akhetonics利用2D材料,如石墨烯,来实现这一目标。这些材料具有极高的非线性系数,正是公司所需要的光晶体管所需的特性。照射在这种材料上的光会改变与之同步穿过材料的脉冲的光密度。Akhetonics使用石墨烯作为饱和吸收体,这意味着在达到一定强度之前,材料是不透明的,一旦达到这个强度,材料就变得透明,允许随后的信号通过。这样的两个开关可以组合成一个门。Akhetonics已经使用氮化硅上的石墨烯构建了一系列不同的光门,与位于德国法兰克福(奥德)的莱布尼茨高性能微电子研究所IHP合作提供代工服务。
结论随着摩尔定律逼近物理极限和成本的不断攀升,传统电子技术面临发展瓶颈。相对地,硅基光电子技术以其卓越的传输效率和低能耗潜力崭露头角,成为新的技术突破口。这一技术通过光学收发器和光 I/O 芯片的应用,不仅预示着数据处理速度的显著提升,而且在能效和系统集成方面也显示出巨大优势。光技术的运用正变得日益广泛,特别是在提高传统芯片间连接速度至Tbps级别、开发专门处理AI任务的基于Mach-Zehnder干涉仪的光处理器,以及构建量子计算机等方面。尽管大部分光计算机目前仍需直接连接至电子控制系统,但全光计算机的开发正在进行中,预计还需几年时间才能融入常规计算系统,届时将实现计算技术的一大飞跃。