 扫码关注
扫码关注

























特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。
1、感知 Occupancy Network
特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的一个概率值。
为什么估计occupancy对自动驾驶感知很重要呢?因为在行驶中,除了常见障碍物如车辆、行人,我们可以通过3D物体检测的方式来估计他们的位置和大小,还有更多长尾的障碍物也会对行驶产生重要影响。例如:1.可变形的障碍物,如两节的挂车,不适合用3D bounding box来表示;2.异形障碍物,如翻倒的车辆,3D姿态估计会失效;3.不在已知类别中的障碍物,如路上的石子、垃圾等,无法进行分类。因此,我们希望能找到一种更好的表达来描述这些长尾障碍物,完整估计3D空间中每一个位置的占据情况(occupancy),甚至是语义(semantics)和运动情况(flow)。
特斯拉用下图的具体例子来展现Occupancy Network的强大。不同于3D的框,occupancy这种表征对物体没有过多的几何假设,因此可以建模任意形状的物体和任意形式的物体运动。图中展示了一个两节的公交车正在启动的场景,蓝色表示运动的体素,红色表示静止的体素,Occupancy Network精确地估计出了公交车的第一节已经开始运动,而第二节还处于静止状态。

对正在启动的两节公交车的occupancy估计,蓝色表示运动的体素,红色表示静止的体素
Occupancy Network的模型结构如下图所示。首先模型利用RegNet和BiFPN从多相机获取特征,这个结构跟去年的AI day分享的网络结构一致,说明backbone变化不大。然后模型通过带3D空间位置的spatial query对2D图像特征进行基于attention的多相机融合。如何实现3D spatial query和2D特征图之间的联系呢?具体融合的方式图中没有细讲,但有很多公开的论文可以参考。我认为最有可能采取的是两种方案之一,第一种叫做3D-to-2D query,即根据每个相机的内外参将3D spatial query投影到2D特征图上,提取对应位置的特征。该方法在DETR3D中提出,BEVFormer和PolarFormer也采取了该思想。第二种是利用positional embedding来进行隐式的映射,即将2D特征图的每个位置加上合理的positional embedding,如相机内外参、像素坐标等,然后让模型自己学习2D到3D特征的对应关系。再接下来模型进行时序融合,实现的方法是根据已知的自车位置和姿态变化,将3D特征空间进行拼接。
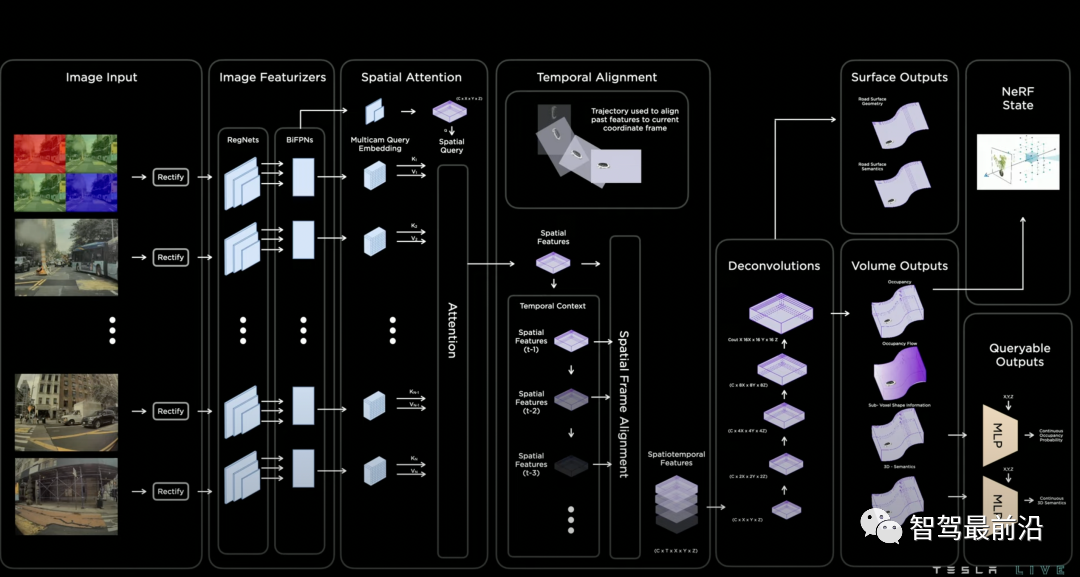
Occupancy Network结构
特征融合后,一个基于deconvolution的解码器会解码出每个3D空间位置的occupancy,semantics以及flow。发布会中强调,由于这个网络的输出是稠密(dense)的,输出的分辨率会受到内存的限制。我相信这也是所有做图像分割的同学们遇到的一大头疼的问题,更何况这里做的是3D分割,但自动驾驶对于分辨率度的要求却很高(~10cm)。因此,受到神经隐式表示(neural implicit representation)的启发,模型的最后额外设计了一个隐式queryable MLP decoder,输入任意坐标值(x,y,z),可解码出该空间位置的信息,即occupancy,semantics,flow。该方法打破了模型分辨率的限制,我认为是设计上的一个亮点。
2、规划 Interactive Planning
规划是自动驾驶的另一个重要模块,特斯拉这次主要强调了在复杂路口对交互(interaction)进行建模。为什么交互建模如此重要呢?因为其他车辆、行人的未来行为都有一定的不确定性,一个聪明的规划模块要在线进行多种自车和他车交互的预测,并且对每一种交互带来的风险进行评估,并最终决定采取何种策略。
特斯拉把他们采用的规划模型叫做交互搜索(Interaction Search),它主要由三个主要步骤组成:树搜索,神经网络轨迹规划和轨迹打分。
1、树搜索是轨迹规划常用的算法,可以有效地发现各种交互情形找到最优解,但用搜索的方法来解决轨迹规划问题遇到的最大困难是搜索空间过大。例如,在一个复杂路口可能有20辆与自车相关,可以组合成超过100种交互方式,而每种交互方式都可能有几十种时空轨迹作为候选。因此特斯拉并没有采用轨迹搜索的方法,而是用神经网络来给一段时间后可能到达的目标位置(goal)进行打分,得到少量较优的目标。
2、在确定目标以后,我们需要确定一条到达目标的轨迹。传统的规划方法往往使用优化来解决该问题,解优化并不难,每次优化大约花费1到5毫秒,但是当前面步骤树搜索的给出的候选目标比较多的时候,时间成本我们也无法负担。因此特斯拉提出使用另一个神经网络来进行轨迹规划,从而对多个候选目标实现高度并行规划。训练这个神经网络的轨迹标签有两种来源:第一种是人类真实开车的轨迹,但是我们知道人开的轨迹可能只是多种较优方案中的一种,因此第二种来源是通过离线优化算法产生的其他的轨迹解。
3、在得到一系列可行轨迹后,我们要选择一个最优方案。这里采取的方案是对得到的轨迹进行打分,打分的方案集合了人为制定的风险指标,舒适指标,还包括了一个神经网络的打分器。
通过以上三个步骤的解耦,特斯拉实现了一个高效的且考虑了交互的轨迹规划模块。基于神经网络的轨迹规划可以参考的论文并不多,我有发表过一篇与该方法比较相关的论文TNT[5],同样地将轨迹预测问题分解为以上三个步骤进行解决:目标打分,轨迹规划,轨迹打分。感兴趣的读者可以前往查阅细节。此外,我们课题组也在一直探究行为交互和规划相关的问题,也欢迎大家关注我们最新的工作InterSim[6]。
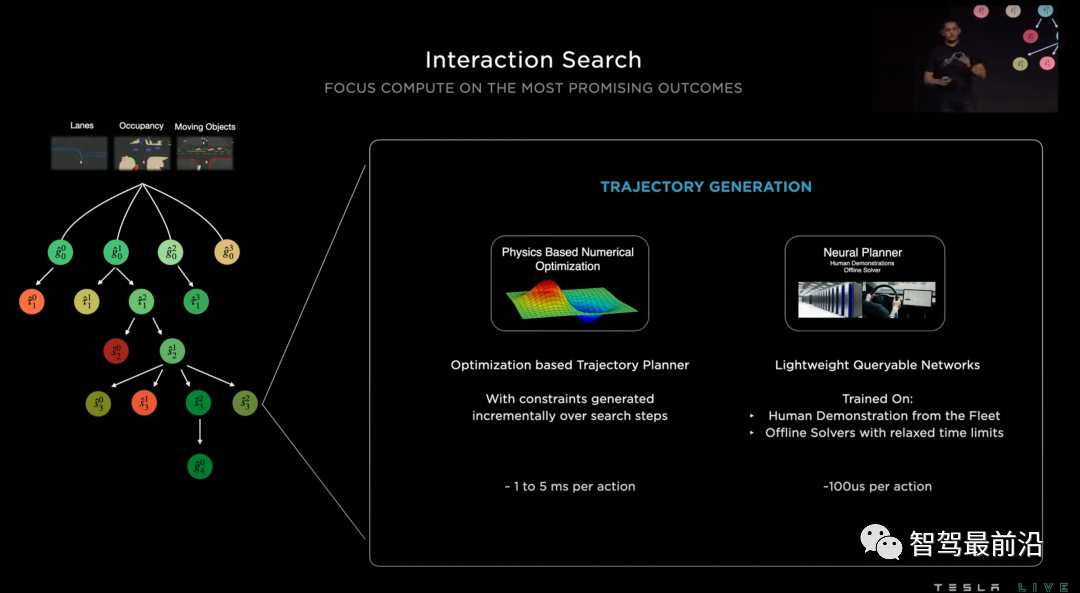
Interaction Search规划模型结构
3、矢量地图 Lanes Network
个人觉得本次AI Day上另一大技术亮点是在线矢量地图构建模型Lanes Network。有关注去年AI Day的同学们可能记得,特斯拉在BEV空间中对地图进行了完整的在线分割和识别。那么为什么还要做Lanes Network呢?因为分割得到的像素级别的车道不足够用于轨迹规划,我们还需要得到车道线的拓扑结构,才能知道我们的车可以从一条车道变换到另一条车道。
我们先来看看什么是矢量地图,如图所示,特斯拉的矢量地图由一系列蓝色的车道中心线centerline和一些关键点(连接点connection,分叉点fork, 并道点merge)组成,并且通过graph的形式表现了他们的连接关系。
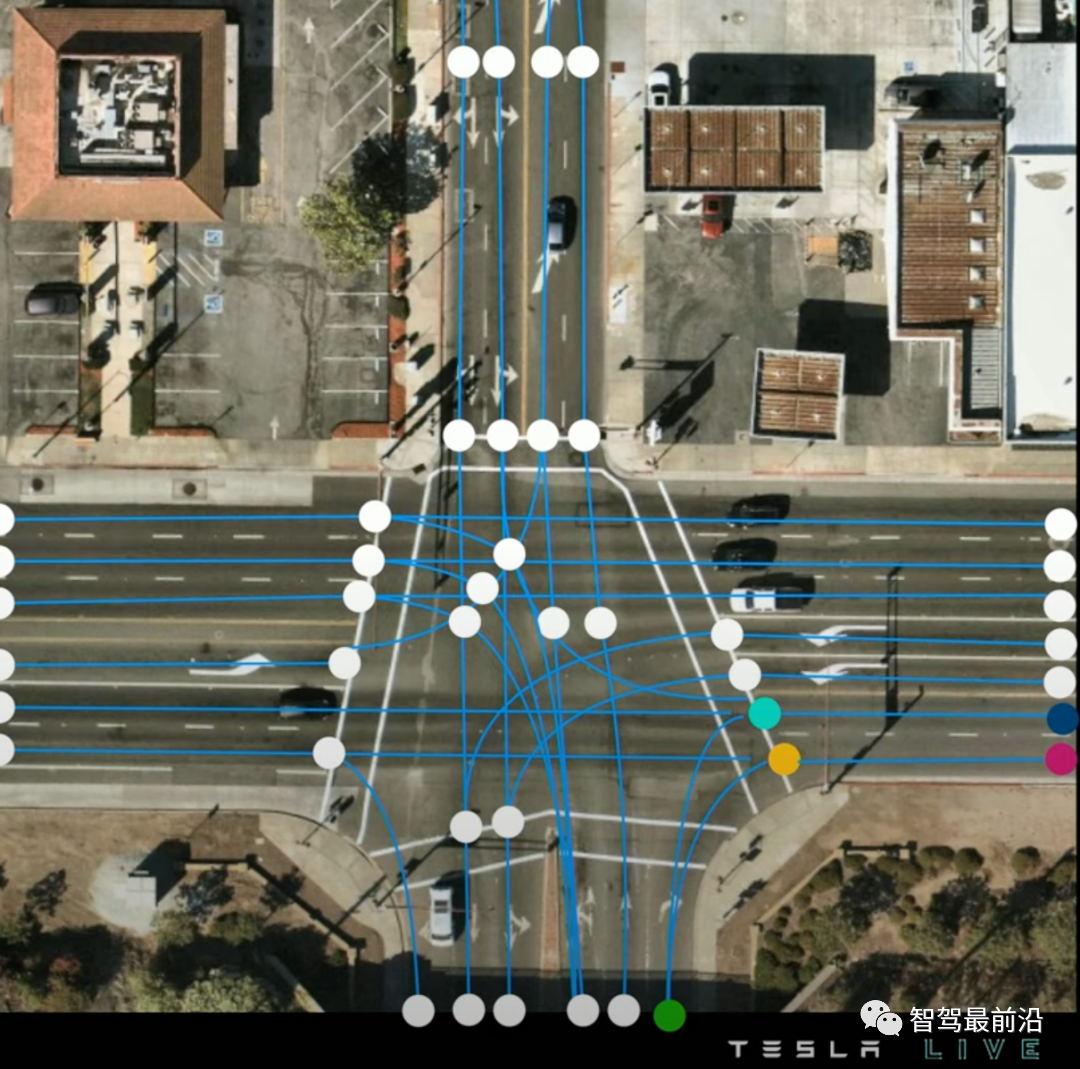
矢量地图,圆点为车道线关键点,蓝色为车道中心线
Lanes Network在模型结构上,是感知网络backbone基础上的一个decoder。相比解码出每个体素的occupancy和语义,解码出一系列稀疏的、带连接关系的车道线更为困难,因为输出的数量不固定,此外输出量之间还有逻辑关系。
特斯拉参考了自然语言模型中的Transformer decoder,以序列的方式自回归地输出结果。具体实现上来说,我们首先要选取一个生成顺序(如从左到右,从上到下),对空间进行离散化(tokenization)。然后我们就可以用Lanes Network进行一系列离散token的预测。如图所示,网络会先预测一个节点的粗略位置的(index:18),精确位置(index:31),然后预测该节点的语义("Start",即车道线的起点),最后预测连接特性,如分叉/并道/曲率参数等。网络会以这样自回归的方式将所有的车道线节点进行生成。
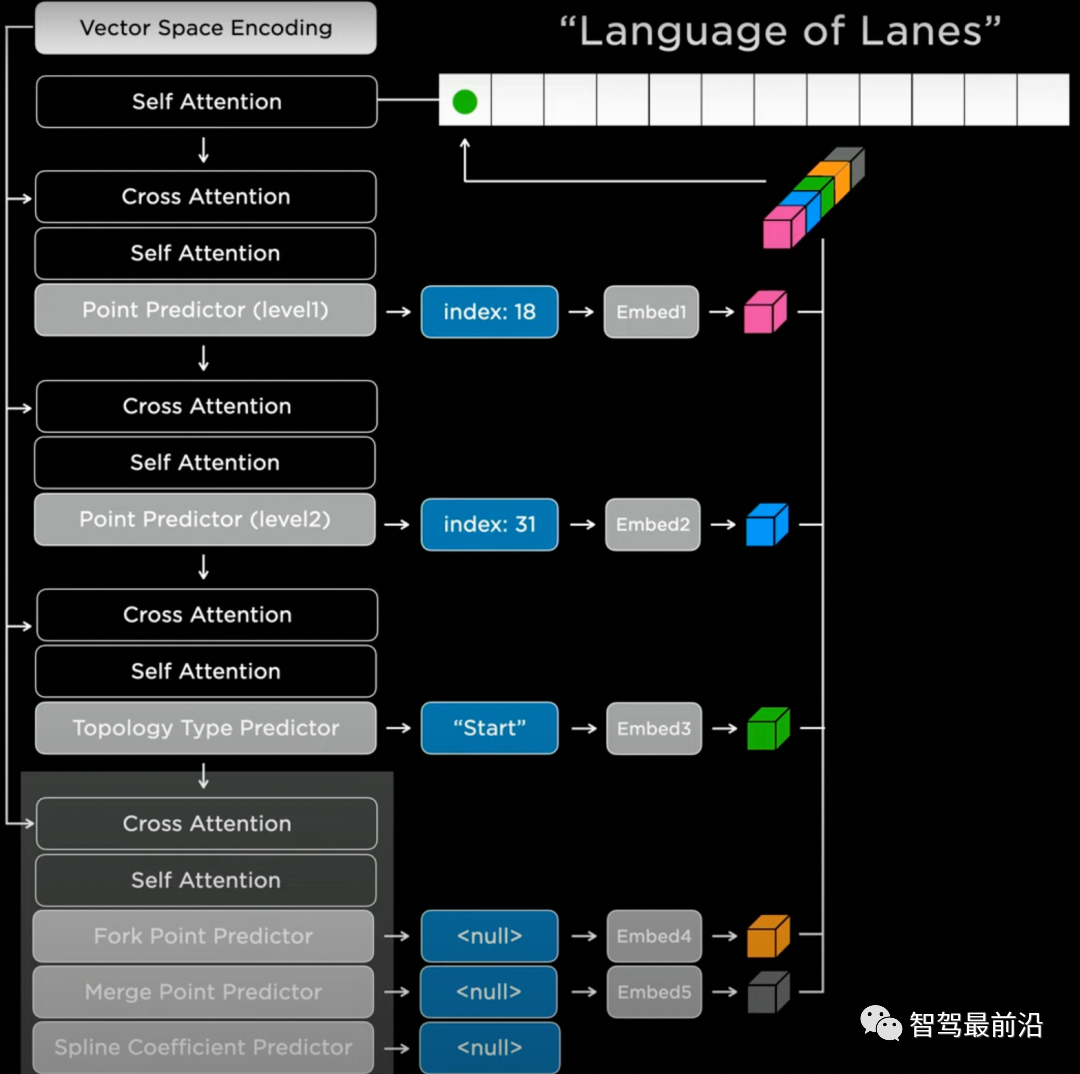
Lanes Network网络结构
我们要注意到,自回归的序列生成并不是语言Transformer模型的专利。我们课题组在过去几年中也有两篇生成矢量地图的相关论文,HDMapGen[7]和VectorMapNet[8]。HDMapGen采用带注意力的图神经网络(GAT)自回归地生成矢量地图的关键点,和特斯拉的方案有异曲同工之妙。而VectorMapNet采用了Detection Transformer(DETR)来解决该问题,即用集合预测(set prediction)的方案来更快速地生成矢量地图。
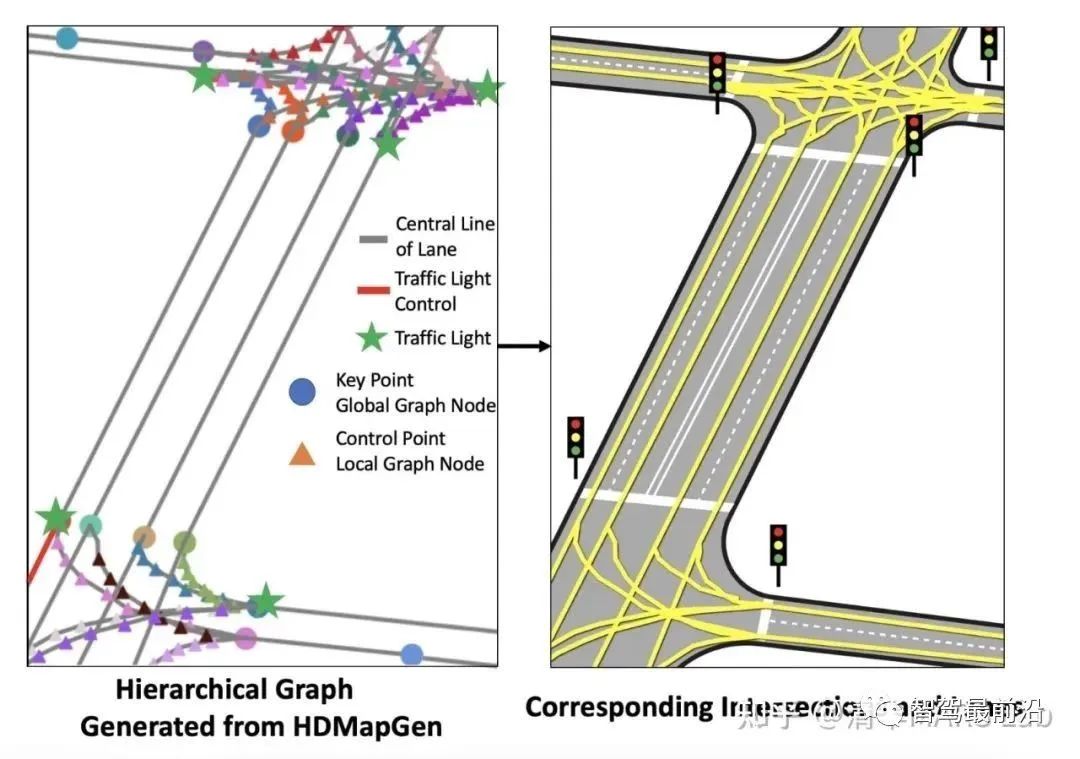
HDMapGen矢量地图生成结果
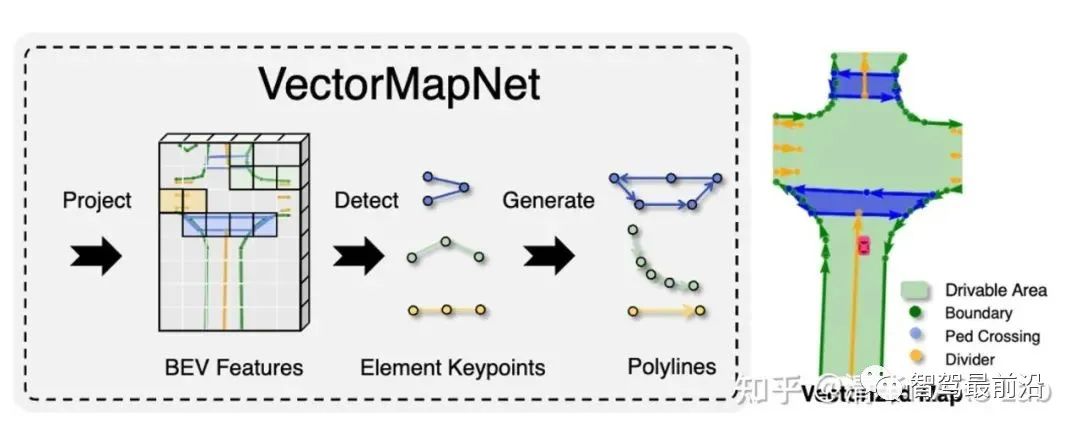
VectorMapNet矢量地图生成结果
4、自动标注 Autolabeling
自动标注也是特斯拉在去年AI Day就讲解过的一种技术,今年的自动标注着重讲解了Lanes Network的自动标注。特斯拉的车每天就能产生500000条驾驶旅程(trip),利用好这些驾驶数据能够更好地帮助进行车道线的预测。
特斯拉的自动车道线标注有三个步骤:
1、通过视觉惯性里程计(visual inertial odometry)技术,对所有的旅程进行高精度轨迹估计。
2、多车多旅程的地图重建,是该方案中的最关键步骤。该步骤的基本动机是,不同的车辆对同一个地点可能有不同空间角度和时间的观测,因此将这些信息进行聚合能更好地进行地图重建。该步骤的技术点包括地图间的几何匹配和结果联合优化。
3、对新旅程进行车道自动标注。当我们有了高精度的离线地图重建结果后,当有新的旅程发生时,我们就可以进行一个简单的几何匹配,得到新旅程车道线的伪真值(pseudolabel)。这种获取伪真值的方式有时候(在夜晚、雨雾天中)甚至会优于人工标注。
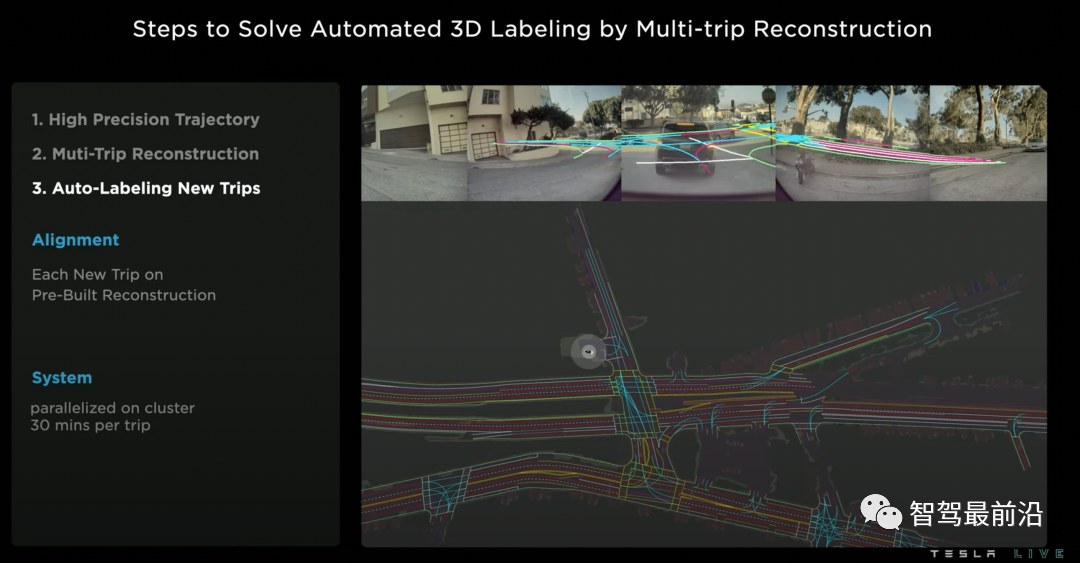
Lanes Network自动标注
5、仿真 Simulation
视觉图像的仿真是近年来计算机视觉方面的热门方向。在自动驾驶中,视觉仿真的主要目的,是有针对性地生成一些少见场景,从而免掉到真实路测中去碰运气的必要。例如,特斯拉常年头疼的路中央横着大卡车的场景。但是视觉仿真并不是一个简单的问题,对于一个复杂的路口(旧金山的Market Street),利用传统建模渲染的方案需要设计师2周的时间。而特斯拉通过AI化的方案,现在只需要5分钟。

视觉仿真重建的路口
具体来说,视觉仿真的先决条件是要准备自动标注的真实世界道路信息 ,和丰富的图形素材库。然后依次进行以下步骤:
1、路面生成:根据路沿进行路面的填充,包括路面坡度、材料等细节信息。
2、车道线生成:将车道线信息在路面上进行绘制。
3、植物和楼房生成:在路间和路旁随机生成和渲染植物和房屋。生成植物和楼房的目的不仅仅是为了视觉的美观,它也同时仿真了真实世界中这些物体引起的遮挡效应。
4、其他道路元素生成:如信号灯,路牌,并且导入车道和连接关系。
5、加入车辆和行人等动态元素。
6、基础设施 Infrastructure
最后,我们简单说说特斯拉这一系列软件技术的基础,就是强大的基础设施。特斯拉的超算中心拥有14000个GPU,共30PB的数据缓存,每天都有500000个新的视频流入这些超级计算机。为了更高效地处理这些数据额,特斯拉专门开发了加速的视频解码库,以及加速读写中间特征的文件格式.smol file format。此外,特斯拉还自研了超算中心的芯片Dojo,我们在这里不做讲解。

视频模型训练的超算中心
7、总结
随着近两年特斯拉AI Day的内容发布,我们慢慢看清了特斯拉在自动(辅助)驾驶方向上的技术版图,同时我们也看到特斯拉自己也在不停地自我迭代,例如从2D感知,BEV感知,到Occupancy Network。自动驾驶是一个万里长征,是什么在支撑特斯拉技术的演进呢?我想是三点:视觉算法带来的全场景理解能力,强大算力支持的模型迭代速度,海量数据带来的泛化性。这不就是深度学习时代的三大支柱吗











![电子设计:频域采样定理及FFT算法[学以致用系列课程之数字信号处理]](https://api.fanyedu.com/uploads/image/5e/e20549b95077812a27c92ed71009cb.png)



































