扫码关注
扫码关注
























从文章标题就知道,这篇文章是介绍些什么。
这是我一位朋友的问题反馈:
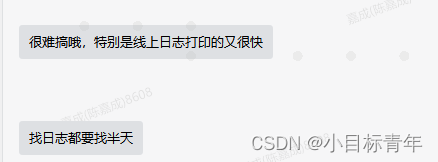
好像是的,确实这种现象是普遍存在的。
有时候一个业务调用链场景,很长,调了各种各样的方法,看日志的时候,各个接口的日志穿插,确实让人头大。
模糊匹配搜索日志能解决吗?能解决一点点。但是不能完全呈现出整个链路相关的日志。
那要做到方便,很显然,我们需要的是把同一次的业务调用链上的日志串起来。
什么效果?先看一个实现后的效果图:
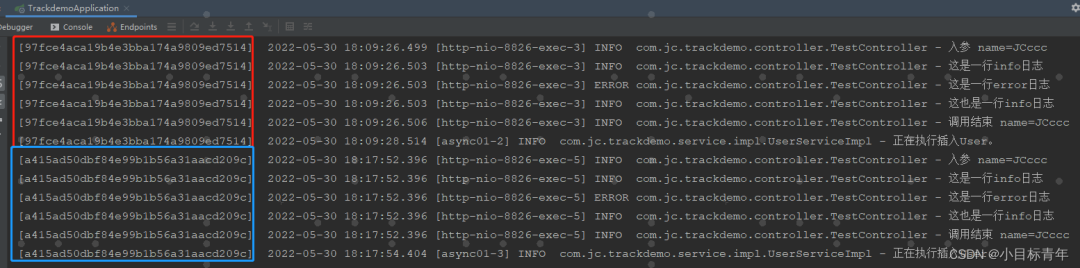
这样下来,我们再配合模糊匹配查找日志,效果不就刚刚的了。
cat -n info.log |grep "a415ad50dbf84e99b1b56a31aacd209c"或者
grep -10 'a415ad50dbf84e99b1b56a31aacd209c' info.log (10是指上下10行)不多说,开整。
正文惯例,先看一眼这次实战最终工程的结构:
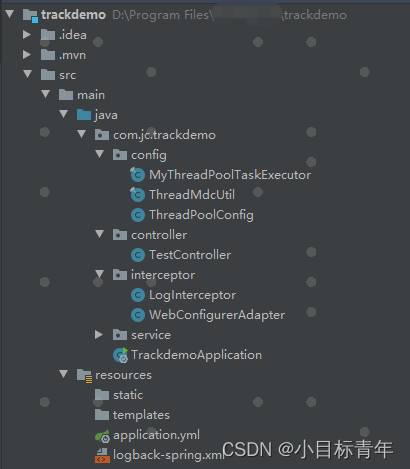
①pom.xml 依赖
②整合logback,打印日志,logback-spring.xml (简单配置下)
application.yml
server: port: 8826 logging: config: classpath:logback-spring.xml③自定义日志拦截器 LogInterceptor.java
用途:每一次链路,线程维度,添加最终的链路ID TRACE_ID。
import org.slf4j.MDC; import org.springframework.lang.Nullable; import org.springframework.util.StringUtils; import org.springframework.web.servlet.HandlerInterceptor; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.util.UUID; /** * @Author: JCccc * @Date: 2022-5-30 10:45 * @Description: */ public class LogInterceptor implements HandlerInterceptor { private static final String TRACE_ID = "TRACE_ID"; @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) { String tid = UUID.randomUUID().toString().replace("-", ""); //可以考虑让客户端传入链路ID,但需保证一定的复杂度唯一性;如果没使用默认UUID自动生成 if (!StringUtils.isEmpty(request.getHeader("TRACE_ID"))){ tid=request.getHeader("TRACE_ID"); } MDC.put(TRACE_ID, tid); return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) { MDC.remove(TRACE_ID); } }MDC(Mapped Diagnostic Context)诊断上下文映射,是@Slf4j提供的一个支持动态打印日志信息的工具。
WebConfigurerAdapter.java 添加拦截器
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; /** * @Author: JCccc * @Date: 2022-5-30 10:47 * @Description: */ @Configuration public class WebConfigurerAdapter implements WebMvcConfigurer { @Bean public LogInterceptor logInterceptor() { return new LogInterceptor(); } @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(logInterceptor()); //可以具体制定哪些需要拦截,哪些不拦截,其实也可以使用自定义注解更灵活完成 // .addPathPatterns("/**") // .excludePathPatterns("/testxx.html"); } }ps: 其实这个拦截的部分改为使用自定义注解 aop也是很灵活的。
到这时候,其实已经完成,就是这么简单。
我们写个测试接口,看下效果:
@PostMapping("doTest") public String doTest(@RequestParam("name") String name) throws InterruptedException { log.info("入参 name={}",name); testTrace(); log.info("调用结束 name={}",name); return "Hello," name; } private void testTrace(){ log.info("这是一行info日志"); log.error("这是一行error日志"); testTrace2(); } private void testTrace2(){ log.info("这也是一行info日志"); }效果(OK的):

还没完。
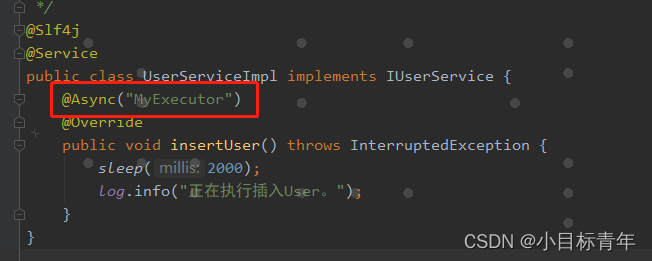
接下来看一个场景, 使用子线程的场景:
故意写一个异步线程,加入这个调用里面:
再次执行看开效果,显然子线程丢失了trackId:
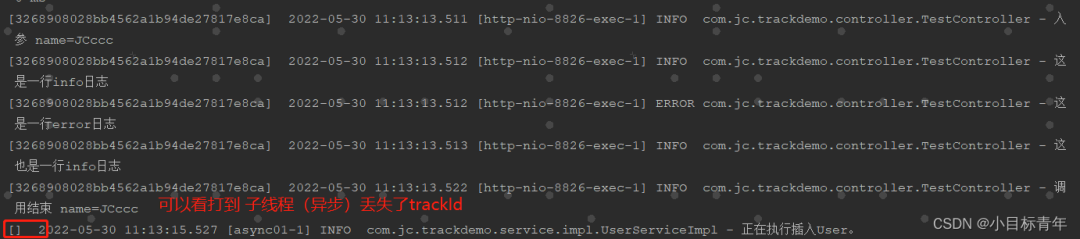
所以我们需要针对子线程使用情形,做调整,思路:将父线程的trackId传递下去给子线程即可。
①ThreadPoolConfig.java 定义线程池,交给spring管理
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.EnableAsync; import java.util.concurrent.Executor; /** * @Author: JCccc * @Date: 2022-5-30 11:07 * @Description: */ @Configuration @EnableAsync public class ThreadPoolConfig { /** * 声明一个线程池 * * @return 执行器 */ @Bean("MyExecutor") public Executor asyncExecutor() { MyThreadPoolTaskExecutor executor = new MyThreadPoolTaskExecutor(); //核心线程数5:线程池创建时候初始化的线程数 executor.setCorePoolSize(5); //最大线程数5:线程池最大的线程数,只有在缓冲队列满了之后才会申请超过核心线程数的线程 executor.setMaxPoolSize(5); //缓冲队列500:用来缓冲执行任务的队列 executor.setQueueCapacity(500); //允许线程的空闲时间60秒:当超过了核心线程出之外的线程在空闲时间到达之后会被销毁 executor.setKeepAliveSeconds(60); //线程池名的前缀:设置好了之后可以方便我们定位处理任务所在的线程池 executor.setThreadNamePrefix("asyncJCccc"); executor.initialize(); return executor; } }② MyThreadPoolTaskExecutor.java 是我们自己写的,重写了一些方法:
import org.slf4j.MDC; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import java.util.concurrent.Callable; import java.util.concurrent.Future; /** * @Author: JCccc * @Date: 2022-5-30 11:13 * @Description: */ public final class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor { public MyThreadPoolTaskExecutor() { super(); } @Override public void execute(Runnable task) { super.execute(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap())); } @Override public③ThreadMdcUtil.java
import org.slf4j.MDC; import java.util.Map; import java.util.UUID; import java.util.concurrent.Callable; /** * @Author: JCccc * @Date: 2022-5-30 11:14 * @Description: */ public final class ThreadMdcUtil { private static final String TRACE_ID = "TRACE_ID"; // 获取唯一性标识 public static String generateTraceId() { return UUID.randomUUID().toString(); } public static void setTraceIdIfAbsent() { if (MDC.get(TRACE_ID) == null) { MDC.put(TRACE_ID, generateTraceId()); } } /** * 用于父线程向线程池中提交任务时,将自身MDC中的数据复制给子线程 * * @param callable * @param context * @param public staticOK,重启服务,再看看效果:
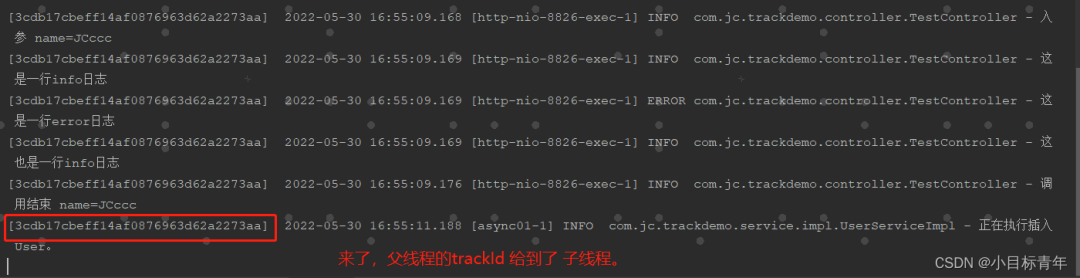
可以看的,子线程的日志也被串起来了。