扫码关注
扫码关注
























苹果最近开始了RISC-V工程师的招聘,作为ARM架构的拥趸,苹果也要开始做两手准备了。
目前ARM可能将被NVIDIA收购,虽然NVIDIA一再保证,ARM会独立运行,但是作为CPU架构应用方,多留一手还是非常有必要的。

苹果的RISC-V招聘需求里面描述,搞RISC-V是为了支持机器学习、视觉算法、信号和视频处理等方面的必要计算。通过紧密集成软件和硬件,推动底层计算的技术水平,最后达到高能效和高性能。
目前苹果有包括 iOS、macOS、watchOS 和 tvOS 的各种嵌入式子系统。目前通过已有的信息综合来看,苹果的RISC-V将来大概率是用在的手表等智能穿戴设备上。
如何满足这些苹果设备对CPU处理能力的需求?
苹果在招聘中明确指出,应聘者应该具备RISC-V和 NEON的技术能力。
RISC-V和ARM的NEON,是不是有点奇怪。
RISC-V和NEON本身没有什么关系,一个是RISC-V指令系统,另一个是ARM的技术架构。
但是这个需求透露了苹果的野心,也暴露了目前RISC-V的短板,那就是RISC-V缺乏SIMD的指令集。
NEON是一种SIMD(单指令多数据)加速器处理器,作为ARM内核的一部分。这意味着在执行一条指令期间,最多可并行处理16个数据集。由于NEON内部存在并行性。它还可以并行执行单精度浮点(浮点)运算。NEON技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成。
GPU则是另一种SIMD架构,GPU内部基本上包含执行大量SIMD计算的核心。因此可以大大提高了图形性能能力。
但是,如果SIMD这么好用,为什么RISC-V放弃它并进行向量处理呢?
RISC-V虽然没有添加SIMD指令集扩展,但是添加了Vector指令集扩展。
自1978年以来,IA-32指令集已从80条增加到大约1400条,主要是由SIMD推动的。因此,x86和ARM的规范和手册非常庞大。
相反,最重要的RISC-V指令的概述可以在在一张双面纸上写完。
大道至简。
除此之外,RISC-V的设计者希望有一个实用的CPU指令集,简单有效,并且经典。而SIMD的指令,每隔几年就会有新的发展,变化很大,就会越来越臃肿。
这个是本质的区别。
RISC-V通过扩展Vector指令集,可以支持向量处理,从而可以作为一个向量处理器(VFP)来使用,即通过Vector指令集扩展实现高效的计算,可以有效应对如机器学习、计算器视觉、多媒体应用等。
RISC-V实现向量处理器(VFP),架构设计也更加精简,和现有CPU的深度流水线设计深度融合,并且资源可以重复利用,其编译的指令条目也比较少。
ARM的也有类似的机制,向量处理的VFP,这是是一种经典的浮点硬件加速器。它并不是SIMD。基本上它对一组输入执行一个操作并返回一个输出。它的目的是加快浮点计算。
向量处理器通过流水来增加性能,SIMD通过并行来增加性能。
VFP通常一次能计算一个,而SIMD通常一次能计算很多。
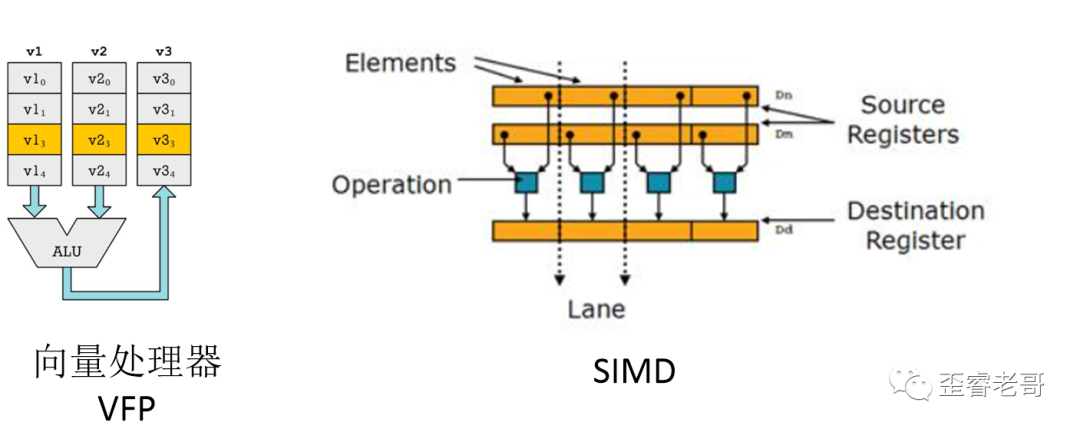
向量处理器(VFP)就像跑车,可以跑的很快,而SIMD就像卡车,可以一次装的很多,是一个重量级的解决方案,从芯片面积上来看,SIMD也比VFP更大一下,当然,频率也更慢一些。
苹果目前招聘RISC-V还要懂NEON,这个就需要在RISC-V的-V扩展指令(VFP)和SIMD(NEON)上来平衡了
就像《让子弹飞》中“让”学里描述的那样。
RISC-V 的Vector向量扩展能不能解决搞机器学习?能,效率低。
NEON(SIMD)能不能搞机器学习?能,面积大。
那么RISC-V加NEON二者融合优化,能不能解决问题。
敢问大哥何方神圣?
鄙人,苹果!